
{kind=link}
One large machine or several small ones? The whole question of scaling hinges on this, and it would be wrong to think it’s simple. Vertical scaling is the first option: you strengthen the existing machine instead of adding ten new ones.
What is vertical scaling?

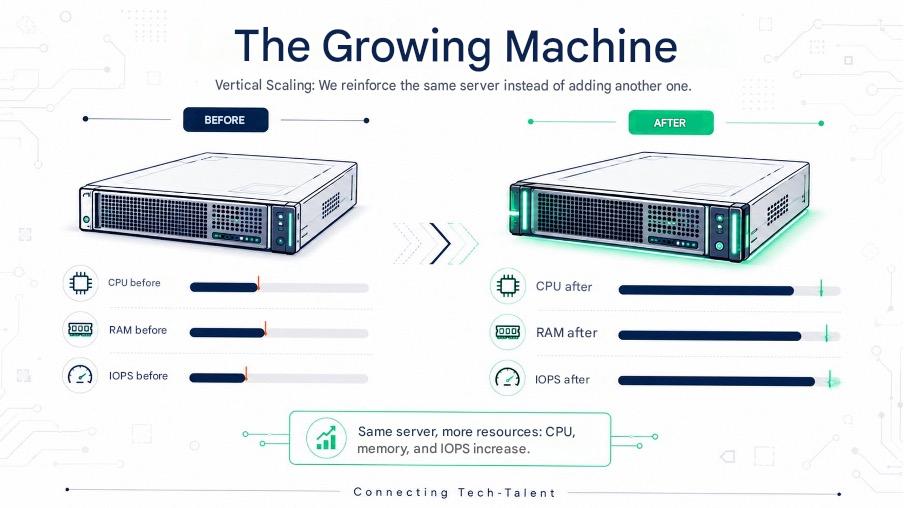
The idea can be summed up in one line: you add power to a single machine rather than multiplying the number of them . That’s scale-up . The existing server gains CPU, RAM, storage, IOPS, and can handle more without changing the topology. No cluster, no load balancer, no new components to wire. The machine simply grows.
And it works both ways. The scale-up increases capacity to absorb a surge or growth; the scale-down decreases when demand drops. There’s no point in paying for a 64GB behemoth that’s just idling on Sunday mornings.
On a public cloud, this resizing takes a few minutes and a restart, not an all-nighter.
The detail that changes everything, and often tips the scales: the application remains completely unchanged. No redesign, no microservices , no network coordination to invent. You keep your code exactly as it is. For many teams, this comfort is invaluable.
Vertical scaling versus horizontal scaling: the match
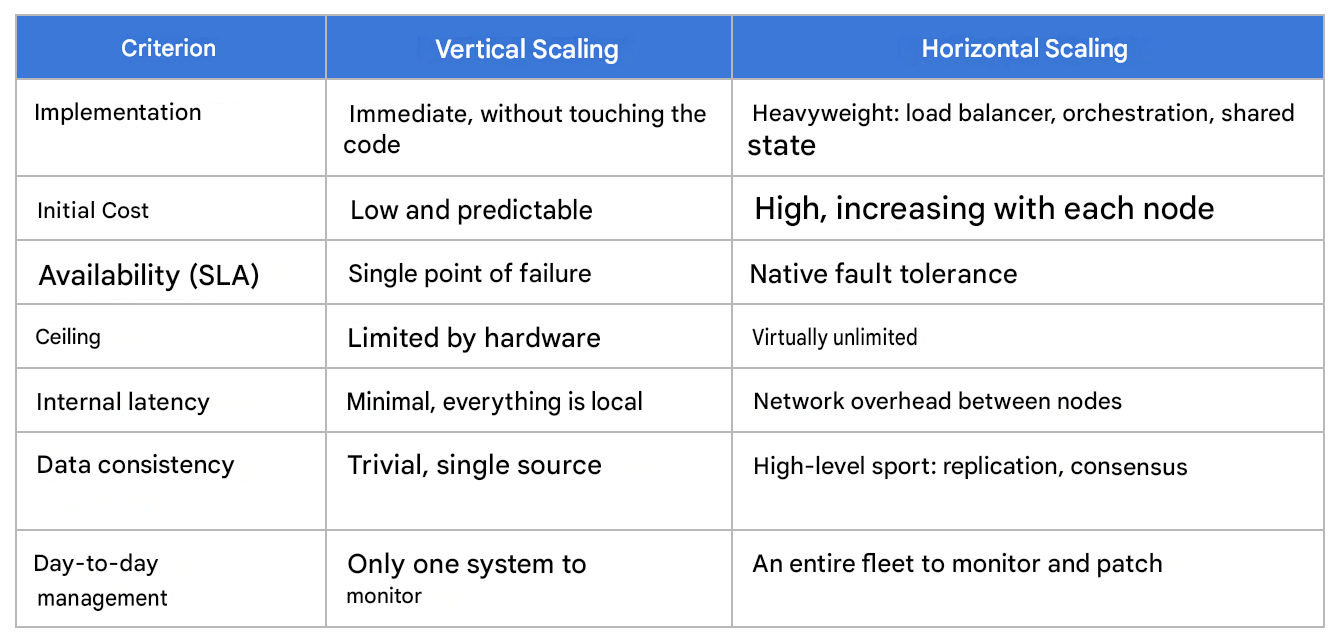
Conversely, horizontal scaling responds to the same pressure with the opposite logic: nodes are added, the load is distributed, and simplicity is traded for a distributed system. The two are not opposed on a single criterion, but on seven. The table speaks for itself:
And between these two extremes? A third way that is almost always forgotten: diagonal scaling . We first strengthen each node vertically, then we replicate them horizontally once they are properly sized.
Let’s be honest: this is where the majority of mature architectures live, halfway, far from dogmas.
What vertical scaling succeeds at, and what it doesn’t forgive
Let’s start with the good news. Its strength lies in its simplicity , and it’s genuine. Not a single line of code to rewrite. Virtually zero internal latency, since everything runs on the same machine. And data consistency that never raises any existential questions: there’s only one source of truth, so no one argues. For a small team, this is a welcome operational relief.
Now, the downsides, because there are some. The single machine remains a single point of failure : if it crashes, the service crashes with it, and then there’s no laughing matter. Resizing often requires a reboot, meaning an interruption window that needs to be carefully orchestrated. And the cost skyrockets at the high end. Doubling the RAM of a small instance? A formality. Doubling that of a behemoth? Get your checkbook ready!
There remains the wall that nothing can penetrate: the physical ceiling . No trick will make a single machine carry a load exceeding the largest size in the catalog. At that point, the question is no longer “will I tip over,” but “when.”
The signals that scream “vertical”
Certain contexts call for vertical scaling without the slightest hesitation . Five signals recur like refrains:
- a predictable charge , which rises smoothly without sudden jolts;
- a stateful workload , difficult to distribute properly;
- a small team , without the manpower to pilot a fleet;
- a strong consistency constraint , typical of transactional;
- a monolith that nobody wants to cut up in a hurry on a Tuesday night.
The use cases naturally follow: relational databases , monolithic applications, development and staging environments, memory-intensive processing… All situations where a single well-sized machine performs better, and costs less, than a hastily assembled cluster.
Typical scenario — “The SaaS that’s starting out”
Three developers, one early access product, a single database, and moderate but steady traffic. Building a cluster here? A waste of engineering time. The vertical absorbs the initial growth, allowing the team to focus on the product, and postpones complexity until it becomes truly necessary.
The decision grid and the cost
Most comparisons stop at a simple “pros/cons” table. Nice try, but it won’t help you decide. Here’s what you need to make a definitive judgment.
First, a scoring grid . Rate your project from 1 to 5 on six criteria, weight them according to your priorities, and see where the balance tips.
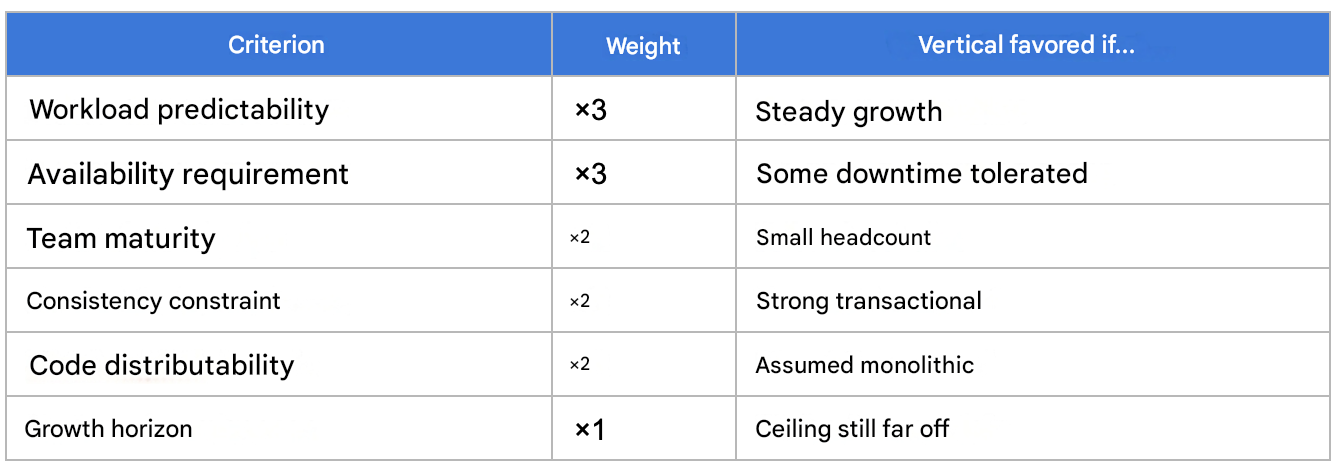
A high scoe suggests vertical growth is within your reach. A low score indicates the need to invest horizontally without delay.
Then there’s the real cost . The price of the instance is just the tip of the iceberg. Hidden beneath the surface are the licenses (often billed per core, and that stings), monitoring, the engineering time required to keep the system running, and the cost of downtime. This last one is always forgotten until the day a profitable service goes down in the middle of the day…
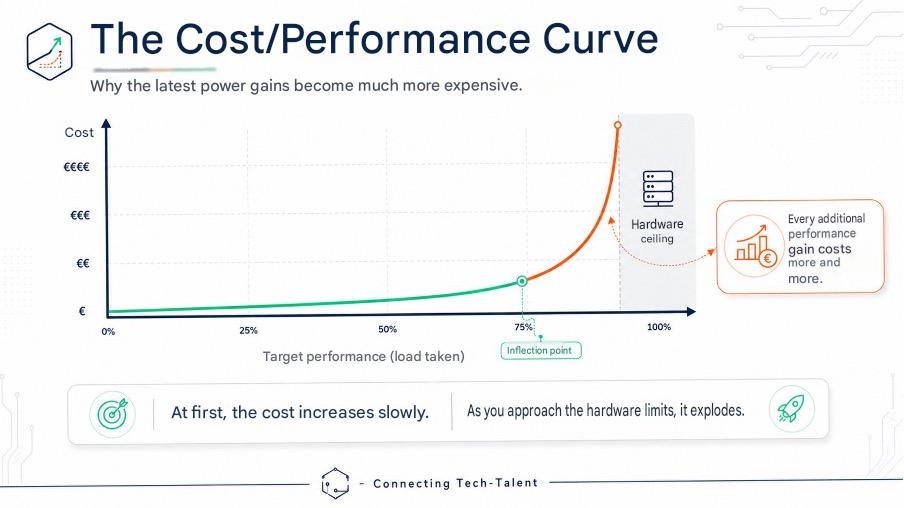
Finally, the tipping point . Vertical construction remains unbeatable as long as the load remains manageable. But its cost curve takes off as it approaches the ceiling, whereas horizontal construction progresses smoothly, in a straight line.
The intersection of the two curves is the crossover point : the moment when adding nodes is cheaper than increasing the machine’s capacity. Identifying this threshold before hitting it will save you from a desperate, fire-fighting migration.
Concrete example: a rapidly growing PostgreSQL database

Concrete examples. A SaaS application whose load doubles every six months. A PostgreSQL database managed at the heart of the system. Should we strengthen the node or replicate it? Let’s follow the trajectory.
At startup, 2 vCPUs and 8 GB of RAM are more than enough. The vertical design is the clear winner. The figures below provide an order of magnitude for monthly costs, which should be refined based on current pricing.
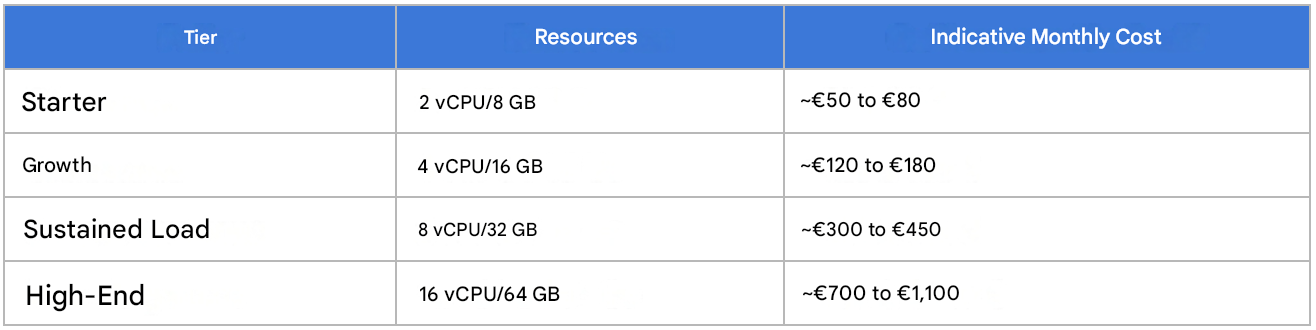
At the lower tiers, OVHcloud and Scaleway often offer more competitive prices than AWS managed instances with the same configuration, especially on storage and outbound traffic, two areas where the gap widens dramatically.
The verdict? Up to 8 vCPUs and 32 GB, the vertical architecture remains the winner: a single database, inherent consistency, and a cost that can be controlled with your eyes closed. Beyond that, the high-end price tag skyrockets, and the fragility of the single node becomes a business risk. This is precisely the moment to add a read replica, then transition to a distributed architecture. And here, beware of misinterpretation: the vertical architecture hasn’t failed. It has done its job perfectly, up to its natural limits. You don’t fault a staircase for not being an elevator.
How to implement vertical scaling without breaking a sweat?
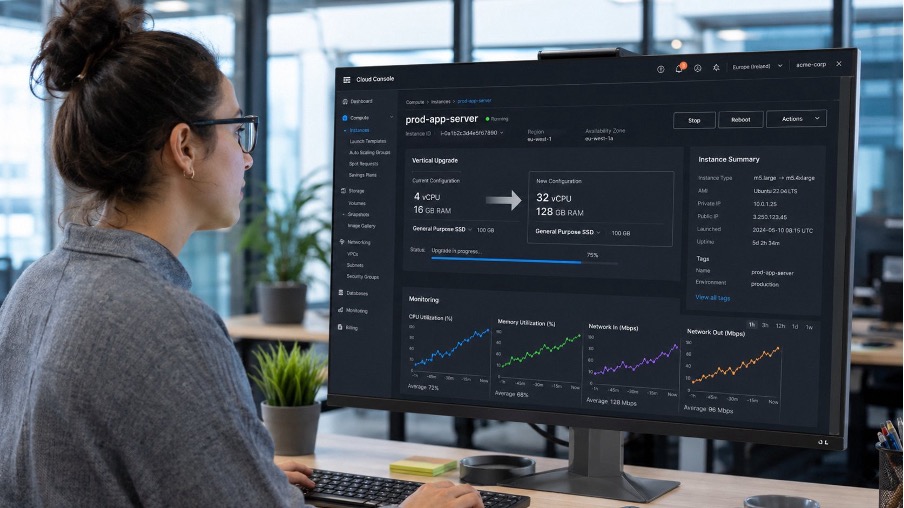
On a cloud VM, resizing always follows the same process: prepare the failover window, change the machine type via the console or API, restart, and verify that the application is running smoothly again. It only takes a few minutes, provided you anticipated the outage rather than being caught off guard.
And yes, it can be automated. On Kubernetes , the Vertical Pod Autoscaler automatically adjusts a pod’s resources based on its actual consumption. On a public cloud, elasticity rules scale the instance up and down according to the thresholds you set. Autopilot exists, so why not use it?
Prepare for what’s next: a smooth exit from the vertical.
Vertical migration has an expiration date. Ignoring it will turn a planned transition into a panicked migration, like a race against time on a Friday at 6 p.m.
It’s best to watch for the signs: increasingly frequent resizes, a marginal cost that skyrockets at each level, an instance that flirts with the largest available size.
Good news, releasing doesn’t mean rewriting everything . It’s prepared in small steps: gradually decoupling the most heavily used components, adding a layer of caching to relieve the base, adding read replicas before even thinking about sharding.
We move from vertical to hybrid, then to horizontal, without any grand finale or night of anguish. The most beautiful trajectories of infra never resemble a revolution; they advance in increments, seemingly without effort.
FAQ about vertical scaling
Does vertical scaling negatively impact performance?
On the contrary, as long as you stay below the ceiling: zero network overhead, internal latency at rock bottom. The problem arises when you stubbornly push beyond the break-even point.
What are its weaknesses?
The single point of failure, the interruption during resizing, the cost spiraling out of control at the high end, and that famous hardware ceiling that cannot be crossed.
What about cloud auto-scaling?
It plays both sides. Vertically, it adjusts the resources of a node; horizontally, it adds or removes instances according to the load.
Can the two be combined?
Of course, this is even the standard practice at maturity: each node is optimized vertically before being replicated horizontally. The best of both worlds, without any effort.
A matter of arbitration, not of faction.
Vertical scaling deserves neither disdain nor blind enthusiasm. It offers simplicity and predictability where horizontal scaling imposes complexity, and it remains the right choice as long as the load is supported below its ceiling. All clarity lies in a single reference point: knowing your tipping point before you hit it.
Architecture that knows where it will break is managed with confidence. Architecture that discovers its ceiling on a Friday night is something to be endured, and it leaves lasting impressions. It is here, far more than in the old vertical versus horizontal debate, that the quality of an infrastructure decision is determined.